.png)

In early December, NeurIPS 2020 ran on Gather. To prepare, the infrastructure team ran a series of simulated load tests. In the process we:
- Broke and fixed our infrastructure (many times)
- Exhausted DigitalOcean capacity in several regions
- Issued so many SSL certificates that we switched SSL providers
- Took down a DigitalOcean load balancer
- And more…
This is the story of that experience.

How We Got Here
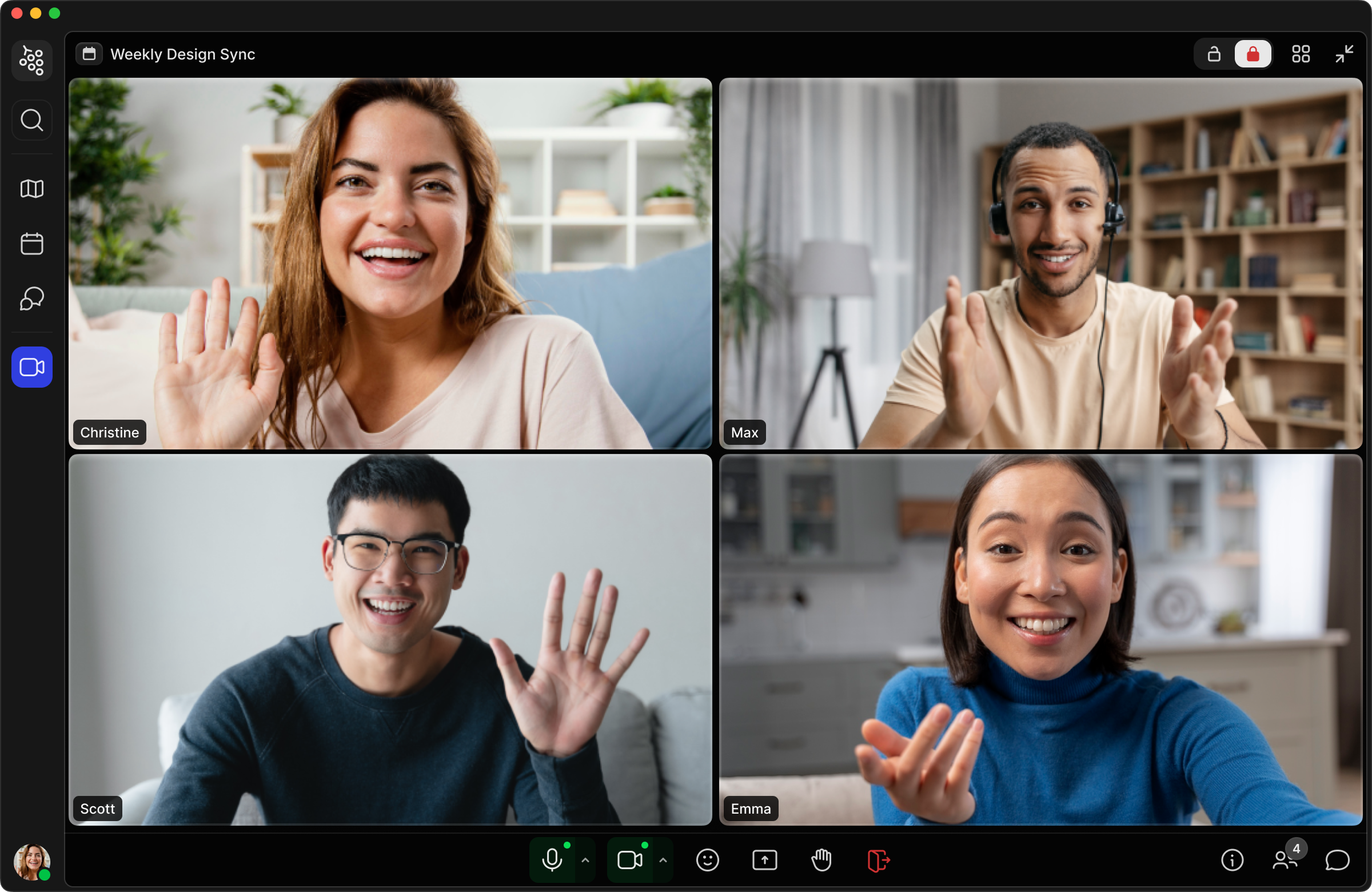
Gather is simultaneously a modern web app, multiplayer video game, and live video chat platform. This means our infrastructure involves several main components:
- An HTTP service to serve the site and API
- A game service to handle real-time game state updates
- A video service to power live video chat
- A database for persistence
We wanted to find the most realistic way to simulate usage of Gather. We therefore developed a "bot test" — using a basic headless browser and Selenium, we simulate a person entering a Gather Space by walking around randomly and using a prerecorded audio/video feed on loop.
Previously, we ran load tests this way with hundreds of bots. We’d spin up a 2 vCPU/4GB machine per bot (the WebRTC stack is rather expensive client-side [1]). Managing a few hundred machines was fine this way with the help of a few scripts.
This time, we wanted to simulate 10,000-15,000 simultaneous participants. So, we turned to Kubernetes.
Architecture

General Kubernetes vocab: a cluster consists of nodes (VMs). Each node can run one or more pods. Each pod can run one or more container. Pods act as "logical hosts" for containers — containers within the same pod can talk to one another via localhost.
In our case, each pod contains two containers: gathertown/gather-town-loadtest and gathertown/standalone-chrome.
- gathertown/gather-town-loadtest is based on the node base image. It contains and runs our JavaScript code, implemented using Selenium.
- gathertown/standalone-chrome is based on the selenium/standalone-chrome base image. It contains our video and audio files, and runs a Selenium Chrome server.
gathertown/gather-town-loadtest communicates with gathertown/standalone-chrome over localhost while running the load test. gathertown/standalone-chrome runs the browser and makes the requests to Gather.
Operating the Load Test
Based on our projections, this load test was going to cost roughly $400-$600/hr depending on the base machine used. The plan was to use 20 Kubernetes clusters and point each cluster to a different Gather Space, simulating load across 20 different concurrent NeurIPS poster session rooms, with 500 bots per room — overall simulating 10k concurrent users on the site.


Overall we ran three load tests:
- 10k bots using 21,760 vCPUs across 20 clusters (680 VMs with 32 vCPUs each)
- 10k bots using 26,720 vCPUs across 20 clusters (3,340 VMs with 8 vCPUs each)
- 15k bots using 40,080 vCPUs across 30 clusters (5,010 VMs with 8 vCPUs each)
The 32 vCPU node type is actually more expensive because those are dedicated vCPUs (as compared to the 8 vCPU node which are shared vCPUs). See footnote [2] explaining the node size choice.
Exceeding Data Center Capacity

With all the prep complete, we were ready to scale to our first test. We began by requesting 20 Kubernetes clusters (34 nodes per cluster, 32 vCPU nodes) in our default region. The first several clusters provisioned without a hitch. But then, things began to slow down. What was going on?
We looked closer at the clusters that were taking forever to provision and noticed something interesting—a notice saying "failed to provision…" for some of the nodes. Thinking there was no possible way we exhausted a region's capacity, we tried provisioning in another region. Lo and behold, provisioning in another region worked… until once again, we were unable to provision.
This pattern continued over the course of several hours while we scrambled to provision enough resources for the load test. Finally, once distributed across many data center regions worldwide, we reached capacity.
I wonder if we're showing up on some DigitalOcean internal dashboard right now.
Sure enough, we were.
The Email
The next morning we got an email from DigitalOcean, suggesting we hop on a call to talk about our use case. Our representative explained,
I reached out to the team and asked if we could suggest any other region globally that we could redirect you and your team to but it turns out that the amount of clusters you are trying to create exceeds capacity in any region.
So we scheduled a call the next day. We were greeted with not one but two representatives from DigitalOcean [3] who spent an hour, free of charge, diving into our full current and future Kubernetes use cases. After all, we weren't just using Kubernetes for this load test—we were already working on moving our whole deployment to Kubernetes.
We learned a tremendous amount from this call, and it could not have been more reassuring for our future DigitalOcean Kubernetes use. Not a single rock was left unturned while discussing hitches we encountered. One of the representatives even offered to hop on a call with us live while we ran our next load test, to direct us to the best regions to use at that moment. We took him up on this offer.
Smooth Sailing
We scheduled a 30-min call with our representative, who recommended a small number of key data centers with enough capacity. We made the request for 20 clusters (this time 167 nodes per cluster, 8 vCPUs nodes). By the end of the 30 min, we were all set to go, with 26,720 vCPUs under our fingertips!
Armed with the knowledge of the best regions to use, when it came time for our third and final load test, we scaled to the full 40k vCPUs on our own without a hitch!
Crashing Our Video System
The Router
While running our first load test, we crashed our staging video infrastructure. Nobody in our office (we dogfood on staging) was able to connect to anybody else. The culprit: our single replica deployment of the video router.
The video router is a WebSocket service that acts as a virtual "phone book" of sorts. When Alice walks up to Bob in Gather, Alice's video will automatically connect to Bob (and vice versa). To do this, Alice needs to know which video server Bob is currently connected to so that she can connect to that video server as well. To find out, she contacts the router over a WebSocket.
When the router fails, the entire video system fails. Nobody can connect to each other anymore. Not to mention the design weakness of a global singular point of failure, the singular router simply could not handle the load.
So, we set out to replicate the router.
Video Server Capacity and Let's Encrypt Rate Limit
Meanwhile, we also found out that we lacked sufficient video servers to handle the load. While provisioning hundreds of more video servers (to take load from any region globally), we ran into Let's Encrypt's 50 new certificates/week rate limit, and switched SSL providers on the fly.
Taking Down a DigitalOcean Load Balancer

With the router replicated, video servers provisioned and hooked up with SSL certs, we were ready for another load test! Within 30 min, we brought up 26,720 vCPUs and started hammering the site.
The video system went down, again. Hmm…
As we investigated deeper we noticed something peculiar: even though the router was down, the individual router servers backing it weren't.
Our new replicated router featured a DigitalOcean load balancer in front of several router replicas. After some further digging we observed that the load balancer returned a 500-series error or completely failed to respond to requests when we exceeded ~6k concurrent WebSocket connections. All the meanwhile, the individual router servers were perfectly responsive and healthy. The load balancer itself was the bottleneck.
It was a Friday at 8:40PM and we decided to email our DigitalOcean representatives. At 10:06 PM we got the following reply:
We're actually in closed beta for two new sizes of Load Balancer, so I'll get you added to that group tomorrow (or certainly by Monday). That will give you access to a big, beefy LB size that should give you a lot more to work with.
As of writing this post, DigitalOcean has released several sizes of load balancers to the public.
40k vCPUs Hammering Prod
By this point, we were two load tests in, gearing up for our third and final load test. We provisioned the video server capacity we needed, replicated our router [4], and were ready to give our production site a proper load test.
Our Video Load Balancing Algorithm Hits an Edge Case
Not long into hammering our live production infrastructure, one of the engineers called out "STOP STOP." Something was going totally sideways with our video infrastructure.
We found that one of our video servers was in an abnormal state, and thus reporting unusual load statistics. The router meanwhile thought that server was lightly loaded. But as more and more people got connected to the malfunctioning video server, the routing algorithm failed to consider that the video server wasn't actually forwarding anybody's video. The one server was a black hole sucking new video connections into it and failing to forward video connections out.
We quickly stopped the load test, disabled the malfunctioning video server, and began rethinking our routing algorithm. After an hour of thinking, we implemented a quick fix to the routing logic and tried again.
The Full Load Test Shakedown
After deploying the new routing algorithm and re-enabling our faulty video server, things were looking good for another load test. We decided to try the following steps to be sure our site was ready:
- Suddenly turning on and off 10k bots to see what happens with a sudden surge in traffic
- Prolonged (1h+) stress under 15k bots to see if anything breaks down longer term


And everything worked! 🚀
Takeaways
There are many ways to load test, but we found this load test left no doubt in our minds as to whether we could bear peak load at NeurIPS 2020. We stressed the limits not only of our own infrastructure, but also of DigitalOcean. We were blown away with the level of free support we received throughout the process and continue to be extremely happy customers.
Lastly, we're hiring! If adventures like these make you excited, we'd love to hear from you.
Footnotes
- Enraged but know how to make this better? We're looking for Software Engineers in Video Systems!
- In early tests, we noticed the master node disconnecting (and becoming unreachable via kubectl) during large cluster scaling events. After some initial back-and-fourth with DigitalOcean support, we (mistakenly) came to understand that larger nodes would help. After all, there'd be fewer nodes in the cluster for the master to deal with and (this next part was a mistake) we thought the master node was the same size as the specified node size. It turns out that the node is entirely managed by DigitalOcean and grows/shrinks depending on the size of the cluster. The key was to provision a large cluster up front to avoid the master resizing on the fly (causing disconnects)—and it didn't matter if we used large or small node types. So, we picked the largest (for pod packing efficiency) shared CPU node type, which was more cost effective than the dedicated CPU variants (see graphs above).
- Thank you so much to our amazing DigitalOcean reps and Darian Wilkin and David Gonzalez for being there for us!
- Now, truth to be told, we didn't end up using the larger LB types. We hit another problem: the load balancer was masking the user IP, which we use for geographic-based assignment of video server. Rather than resolving this and relying on a beta LB, we went for a simple workaround: randomized video router assignment, client-side. We were confident we far over-provisioned the router, so didn't have to worry about discovering new routers or needing to potentially redeploy the client code.
In early December, NeurIPS 2020 ran on Gather. To prepare, the infrastructure team ran a series of simulated load tests. In the process we:
- Broke and fixed our infrastructure (many times)
- Exhausted DigitalOcean capacity in several regions
- Issued so many SSL certificates that we switched SSL providers
- Took down a DigitalOcean load balancer
- And more…
This is the story of that experience.
How We Got Here
Gather is simultaneously a modern web app, multiplayer video game, and live video chat platform. This means our infrastructure involves several main components:
- An HTTP service to serve the site and API
- A game service to handle real-time game state updates
- A video service to power live video chat
- A database for persistence
We wanted to find the most realistic way to simulate usage of Gather. We therefore developed a "bot test" — using a basic headless browser and Selenium, we simulate a person entering a Gather Space by walking around randomly and using a prerecorded audio/video feed on loop.
Previously, we ran load tests this way with hundreds of bots. We’d spin up a 2 vCPU/4GB machine per bot (the WebRTC stack is rather expensive client-side [1]). Managing a few hundred machines was fine this way with the help of a few scripts.
This time, we wanted to simulate 10,000-15,000 simultaneous participants. So, we turned to Kubernetes.
Architecture
General Kubernetes vocab: a cluster consists of nodes (VMs). Each node can run one or more pods. Each pod can run one or more container. Pods act as "logical hosts" for containers — containers within the same pod can talk to one another via localhost.
In our case, each pod contains two containers: gathertown/gather-town-loadtest and gathertown/standalone-chrome.
- gathertown/gather-town-loadtest is based on the node base image. It contains and runs our JavaScript code, implemented using Selenium.
- gathertown/standalone-chrome is based on the selenium/standalone-chrome base image. It contains our video and audio files, and runs a Selenium Chrome server.
gathertown/gather-town-loadtest communicates with gathertown/standalone-chrome over localhost while running the load test. gathertown/standalone-chrome runs the browser and makes the requests to Gather.
Operating the Load Test
Based on our projections, this load test was going to cost roughly $400-$600/hr depending on the base machine used. The plan was to use 20 Kubernetes clusters and point each cluster to a different Gather Space, simulating load across 20 different concurrent NeurIPS poster session rooms, with 500 bots per room — overall simulating 10k concurrent users on the site.
Overall we ran three load tests:
- 10k bots using 21,760 vCPUs across 20 clusters (680 VMs with 32 vCPUs each)
- 10k bots using 26,720 vCPUs across 20 clusters (3,340 VMs with 8 vCPUs each)
- 15k bots using 40,080 vCPUs across 30 clusters (5,010 VMs with 8 vCPUs each)
The 32 vCPU node type is actually more expensive because those are dedicated vCPUs (as compared to the 8 vCPU node which are shared vCPUs). See footnote [2] explaining the node size choice.
Exceeding Data Center Capacity
With all the prep complete, we were ready to scale to our first test. We began by requesting 20 Kubernetes clusters (34 nodes per cluster, 32 vCPU nodes) in our default region. The first several clusters provisioned without a hitch. But then, things began to slow down. What was going on?
We looked closer at the clusters that were taking forever to provision and noticed something interesting—a notice saying "failed to provision…" for some of the nodes. Thinking there was no possible way we exhausted a region's capacity, we tried provisioning in another region. Lo and behold, provisioning in another region worked… until once again, we were unable to provision.
This pattern continued over the course of several hours while we scrambled to provision enough resources for the load test. Finally, once distributed across many data center regions worldwide, we reached capacity.
I wonder if we're showing up on some DigitalOcean internal dashboard right now.
Sure enough, we were.
The Email
The next morning we got an email from DigitalOcean, suggesting we hop on a call to talk about our use case. Our representative explained,
I reached out to the team and asked if we could suggest any other region globally that we could redirect you and your team to but it turns out that the amount of clusters you are trying to create exceeds capacity in any region.
So we scheduled a call the next day. We were greeted with not one but two representatives from DigitalOcean [3] who spent an hour, free of charge, diving into our full current and future Kubernetes use cases. After all, we weren't just using Kubernetes for this load test—we were already working on moving our whole deployment to Kubernetes.
We learned a tremendous amount from this call, and it could not have been more reassuring for our future DigitalOcean Kubernetes use. Not a single rock was left unturned while discussing hitches we encountered. One of the representatives even offered to hop on a call with us live while we ran our next load test, to direct us to the best regions to use at that moment. We took him up on this offer.
Smooth Sailing
We scheduled a 30-min call with our representative, who recommended a small number of key data centers with enough capacity. We made the request for 20 clusters (this time 167 nodes per cluster, 8 vCPUs nodes). By the end of the 30 min, we were all set to go, with 26,720 vCPUs under our fingertips!
Armed with the knowledge of the best regions to use, when it came time for our third and final load test, we scaled to the full 40k vCPUs on our own without a hitch!
Crashing Our Video System
The Router
While running our first load test, we crashed our staging video infrastructure. Nobody in our office (we dogfood on staging) was able to connect to anybody else. The culprit: our single replica deployment of the video router.
The video router is a WebSocket service that acts as a virtual "phone book" of sorts. When Alice walks up to Bob in Gather, Alice's video will automatically connect to Bob (and vice versa). To do this, Alice needs to know which video server Bob is currently connected to so that she can connect to that video server as well. To find out, she contacts the router over a WebSocket.
When the router fails, the entire video system fails. Nobody can connect to each other anymore. Not to mention the design weakness of a global singular point of failure, the singular router simply could not handle the load.
So, we set out to replicate the router.
Video Server Capacity and Let's Encrypt Rate Limit
Meanwhile, we also found out that we lacked sufficient video servers to handle the load. While provisioning hundreds of more video servers (to take load from any region globally), we ran into Let's Encrypt's 50 new certificates/week rate limit, and switched SSL providers on the fly.
Taking Down a DigitalOcean Load Balancer
With the router replicated, video servers provisioned and hooked up with SSL certs, we were ready for another load test! Within 30 min, we brought up 26,720 vCPUs and started hammering the site.
The video system went down, again. Hmm…
As we investigated deeper we noticed something peculiar: even though the router was down, the individual router servers backing it weren't.
Our new replicated router featured a DigitalOcean load balancer in front of several router replicas. After some further digging we observed that the load balancer returned a 500-series error or completely failed to respond to requests when we exceeded ~6k concurrent WebSocket connections. All the meanwhile, the individual router servers were perfectly responsive and healthy. The load balancer itself was the bottleneck.
It was a Friday at 8:40PM and we decided to email our DigitalOcean representatives. At 10:06 PM we got the following reply:
We're actually in closed beta for two new sizes of Load Balancer, so I'll get you added to that group tomorrow (or certainly by Monday). That will give you access to a big, beefy LB size that should give you a lot more to work with.
As of writing this post, DigitalOcean has released several sizes of load balancers to the public.
40k vCPUs Hammering Prod
By this point, we were two load tests in, gearing up for our third and final load test. We provisioned the video server capacity we needed, replicated our router [4], and were ready to give our production site a proper load test.
Our Video Load Balancing Algorithm Hits an Edge Case
Not long into hammering our live production infrastructure, one of the engineers called out "STOP STOP." Something was going totally sideways with our video infrastructure.
We found that one of our video servers was in an abnormal state, and thus reporting unusual load statistics. The router meanwhile thought that server was lightly loaded. But as more and more people got connected to the malfunctioning video server, the routing algorithm failed to consider that the video server wasn't actually forwarding anybody's video. The one server was a black hole sucking new video connections into it and failing to forward video connections out.
We quickly stopped the load test, disabled the malfunctioning video server, and began rethinking our routing algorithm. After an hour of thinking, we implemented a quick fix to the routing logic and tried again.
The Full Load Test Shakedown
After deploying the new routing algorithm and re-enabling our faulty video server, things were looking good for another load test. We decided to try the following steps to be sure our site was ready:
- Suddenly turning on and off 10k bots to see what happens with a sudden surge in traffic
- Prolonged (1h+) stress under 15k bots to see if anything breaks down longer term
And everything worked! 🚀
Takeaways
There are many ways to load test, but we found this load test left no doubt in our minds as to whether we could bear peak load at NeurIPS 2020. We stressed the limits not only of our own infrastructure, but also of DigitalOcean. We were blown away with the level of free support we received throughout the process and continue to be extremely happy customers.
Lastly, we're hiring! If adventures like these make you excited, we'd love to hear from you.
Footnotes
- Enraged but know how to make this better? We're looking for Software Engineers in Video Systems!
- In early tests, we noticed the master node disconnecting (and becoming unreachable via kubectl) during large cluster scaling events. After some initial back-and-fourth with DigitalOcean support, we (mistakenly) came to understand that larger nodes would help. After all, there'd be fewer nodes in the cluster for the master to deal with and (this next part was a mistake) we thought the master node was the same size as the specified node size. It turns out that the node is entirely managed by DigitalOcean and grows/shrinks depending on the size of the cluster. The key was to provision a large cluster up front to avoid the master resizing on the fly (causing disconnects)—and it didn't matter if we used large or small node types. So, we picked the largest (for pod packing efficiency) shared CPU node type, which was more cost effective than the dedicated CPU variants (see graphs above).
- Thank you so much to our amazing DigitalOcean reps and Darian Wilkin and David Gonzalez for being there for us!
- Now, truth to be told, we didn't end up using the larger LB types. We hit another problem: the load balancer was masking the user IP, which we use for geographic-based assignment of video server. Rather than resolving this and relying on a beta LB, we went for a simple workaround: randomized video router assignment, client-side. We were confident we far over-provisioned the router, so didn't have to worry about discovering new routers or needing to potentially redeploy the client code.
- Open the template as a Notion Page, Google Doc, or Slide Deck.
- Make a copy and modify the text so it’s personalized for your team.
- Share the guide at the start of your pilot or before onboarding a new member.
Start your free trial
Experience the #1 virtual office for yourself and build a workspace where remote work doesn’t feel remote.